
PriorDepth
GitHub Link
Project Presentation
As a part of Advanced Topics in 3D Computer Vision Practical, this project aimed at building a model that can provide the depth of the object as well as the movement of the camera from a video sequence. This model combined two the state of the art deep learning-based models
-
KeyPointNet as proposed in Neural Outlier Rejection for Self-Supervised Keypoint Learning for the estimation of the most descriptive key points in an image
-
DepthNet from the research paper MonoDepth2 - Digging Into Self-Supervised Monocular Depth Estimation that aimed at monocular depth estimation. Using only an RGB image, the network is trained to output the relative depth of the objects in an image.
A network design was conceptualized that can be trained end-end on autonomous driving datasets such as KITTI Vision Benchmark Suite. The architecture is shown in the image below.
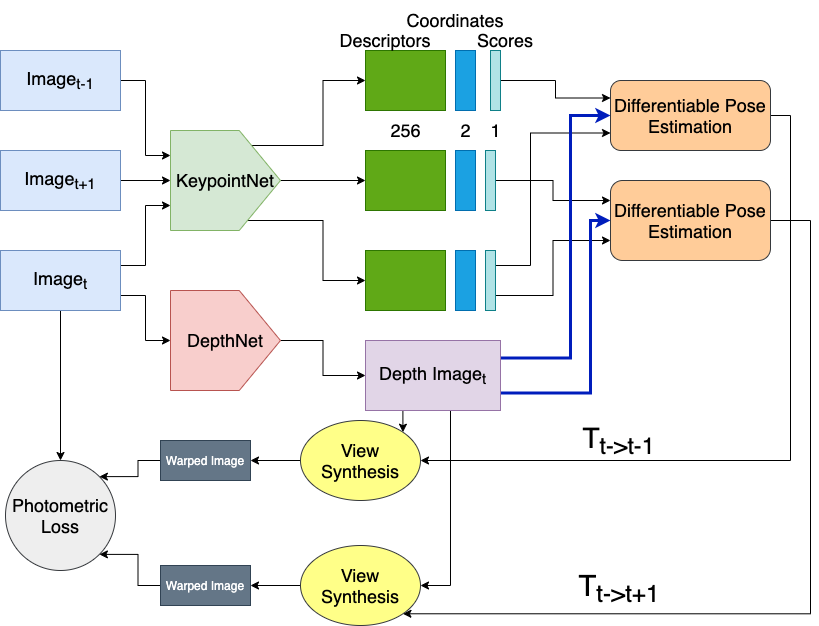
.
The DepthNet was trained on a separate sequence using transfer learning techniques to help the model adapt to the KITTI sequence since the model was originally trained on it. The images below show the input video sequence and the predicted depth from the model.

.

.
The keypoints obtained from trained KeyPointNet are further filtered based on descriptor distance and matching scores to enable a more robust matching. The figures below show the keypoint matches before and application of the intelligent distance based filters.

.

.